
孔子老人家曾经曰过,食色性也。(有小伙伴指出了 其实是孟子说的。。。)今天咱不讲色,就讲讲这个食字。俗话说民以食为天,这吃饱了干活才不累嘛,奈何世面上的饭店多如牛毛,良莠不齐,经常你花了大价钱结果发现不好吃。可这饭入口中方知好坏啊,吃也吃了总不能不给钱吧,那股子憋屈劲就别提了。于是乎,我就想着看看这成千上万家饭店它到底是怎么回事,有什么规律,能不能找出一个判别一家店值不值的方法来。
时值此刻,刚好看到了
分享了一个关于大众点评的数据,共爬取了58万条记录。这可真是刚想睡觉就有人递枕头啊,再好不过了,省了自己爬取数据的功夫了。看了下数据也都挺规整的,那就。。。。直接开干吧。本文主要分4个方面:数据处理、数据分析、机器学习、总结思考。
一、数据处理
1.数据去重
首先,先来查看下数据。啊哈,共有585915条数据,10个维度。
“City”表示所属城市,共有49个热门城市;“Cuisine”表示所属菜系,共有72种不同菜系;“Name”表示饭店名字,共有231877个;“Star”表示星级,取值为0、20、30、35、40、45、50;“Comments”表示评论数量;“PCC”表示人均消费;“Taste”表示口味评分,取值从0到10;“Environment”表示环境评分,取值从0到10;“Service”表示服务评分,取值从0到10;“Addr”表示地址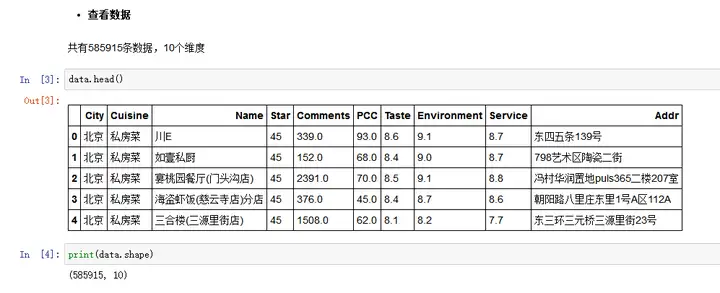
然而我发现这些数据中有不少是重复的,鉴于餐厅可能有分店所以名字重复可以理解(其实不能,分店也要加上XX分店呀~不过好像大众点评没那么严格?),所以我选取了地址作为衡量标准,无论如何地址都应该是唯一的,如果两家店地址重复了,那我只能认为他们是一家店了~ 这样经过去重后,发现数量由585915降到了516674,少了将近7000条数据~~

2.缺失值处理
接下来在看看缺失值得情况。
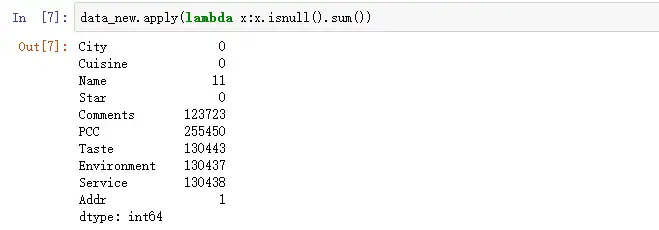
“Name” 字段有11个缺失值,鉴于名字是一个餐厅必不可少的要素,所以对这11家缺少名字的餐厅予以删除惩罚(喂~你们什么态度,连名字都懒得起?)“Addr”同理,没地址我可找不到你啊。然后对于“Taste”、“Environment”、“Service”以及“Comments”和“PCC”都存在缺失值的数据,我本来是想打算给他们回填0处理的,但是转念一想,我是想找出优秀的餐厅啊,那么这些“三无”餐厅对于整体分析没有帮助,是冗余值。而且还会在计算平均值等各项指标时造成误差,所以我决定“狠心”把他们都删除了。
当然有些“三无”餐厅可能只是刚刚开业的新餐厅因为时间太短还没有积攒到评价,确实会存在一部分的误杀情况。不过去新餐厅就餐也是有风险的,我这次只想来个保险的分析。So,等你们攒够了足够的评分再来入选吧,相信是金子总会发光的。
删去缺失值后,数据减少了差不多一半,这说明至少在这次的数据集中大众点评上将近一半的店铺是有缺失关键信息的,不能对我们以很好的指引。点评君你还要加油啊~

嗯,这下数据就干净了~~~~
3. 构建特征
接下来为了后面在分析口味等评分时更方便,我在这里构建了一个新的特征——“overall”(综合分),既‘口味’、‘环境’及‘服务’三者的平均分,精度取一位小数。

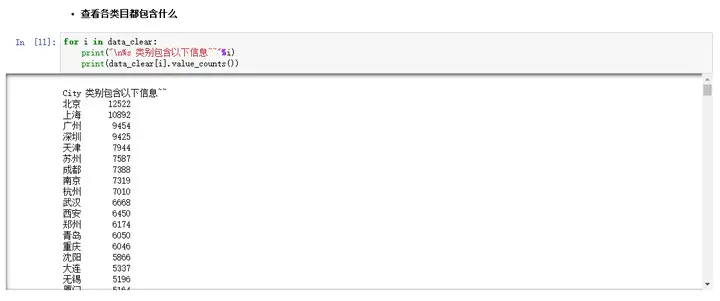
最后在对处理后的数据有个直观的了解,看看每个类目都包含了哪些数据~
二、数据分析(EDA)
1.整体分析
餐厅数量
我们先来看看全国的情况:
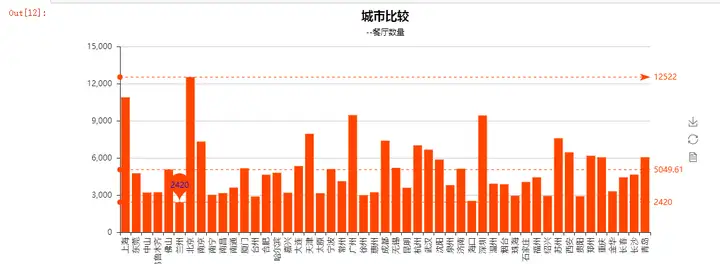
可以看出餐厅数量最多的还是北上广深四个一线城市,其中帝都的数量是最多的共有12522间餐厅(帝都人民好幸福~),最少的是兰州(呃,宇宙第一店兰州拉面的大本营啊,没想到数量最少)。广深两座城市数量基本持平,不愧是我专吃福建人的大吃省(大雾~)。
这在一定程度上也反应出了城市的发展程度,毕竟民以食为天,人口净流入大的城市其饭店等基础民生的设施也更多。除北上广深四大一线城市外,像南京、天津、成都、杭州等明星二线城市饭店数量也很突出,都超过了平均值,而像一些欠发达地区饭店数量则较少,基本符合前面的分析~ 其实不难理解,像广阔的大西北除了旅游景点外都见不到几个人还怎么开店 哈哈(为啥我知道,,因为我刚刚去完回来啊,大西北的景色真心漂亮,强烈安利~)
菜系种类
再来看看哪个城市菜品对多样化,菜系最多:
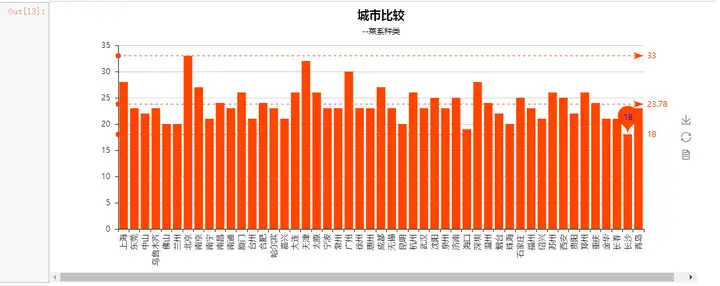
一线城市依然名列前茅,符合预期。帝都力压群雄,拔得头筹,不过令我感到惊讶的是天津竟然仅以一票之差屈居第二。在我想来菜品最多样化的城市应该都是外来人口流入巨大的城市,因为城市聚集了天南海北各地的人,大家口味不同自然就有了不同菜系的市场。而在一个历史相对悠久,人口流动并不是特别大的城市,绵长的历史早就使得当地人培养出了自己的饮食文化,因而种类不会特别多,所以对天津这么高的成绩我表示出了惊讶(最近刚看完河神,对老天津卫独特的文化还挺感兴趣的~)。不过这也说明,天津作为直辖市之一,发展的越来越好了,潜力巨大。与此相似的还有成都、南京、杭州等热门二线城市。
同时,菜系种类的多寡也能反映出一个城市的包容度及本土文化的强势程度。种类多说明城市的包容性强,而种类少说明本土的饮食文化非常强势,挤压甚至同化了不少其他种类,譬如多少爽朗的北方爷们爱上了精致的广东早茶,又有多少吃不得辣的人一把鼻涕一把泪的在川菜馆里大快朵颐~(不过这一点在本次分析中存疑,因为按照这个思路下去的话北京的本土文化不够强势?长沙包容性最低?我以为并不见得~不过暂时我还没想明白是什么原因造成的这些认知偏差,留待后续改进思考,但我怀疑其中一个原因可能是因为本次数据并非全量数据造成的。)
整体角度
让我们在从整体角度看一看:
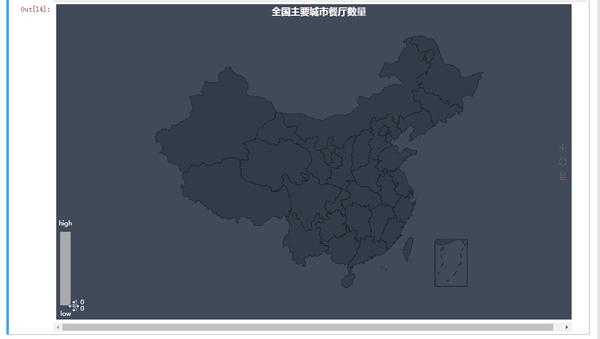
可以看出本次采样的49个城市中,饭店大多集中在东南沿海,尤其是长三角和珠三角地区,另外京津冀地区虽然并非沿海区域,但靠着帝都威名也同样聚集了大量的饭店。这也大体反应出了我国地域经济形势及发展态势,东南沿海发达,西北地区欠发达的形势并没有得到太大的改善,祖国的发展还需要靠我们来建设啊。另外,再次强调,本次分析数据并非全量数据,所以可能只是反映了一部分情况,真实情况或许不同~
2. 深圳情况
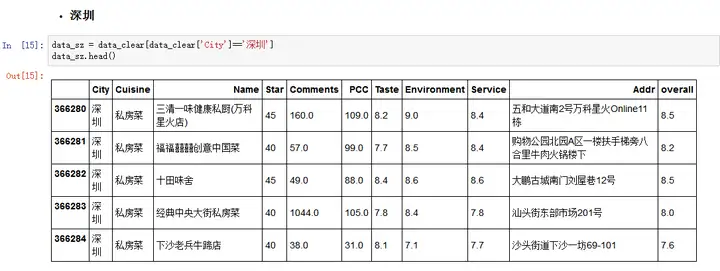
接下来让我们聚焦到单个城市看一看,因为本人居住在深圳,所以我就来看看深圳的情况~~首先定位到深圳,查看下深圳的数据。
餐厅星级
让我们先从星级开始吧~~
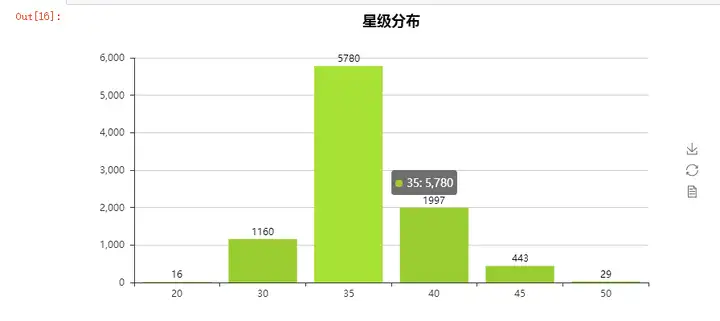
星级分布符合正态分布,主要集中在3.5星附近,2星和5星的都很少(1星数据清理时已去除)。3.5星的基本上是其他星级之和,而从3.5星到4星的数量陡然下降,说明4星是一个非常大的瓶颈,想要突破对于大部分店家而言难度不小。绝大部分店家在达到一个平均水准(3.5星)后就停留在这里了,很难做的更好。而从3星到3.5星的陡然提升也说明3星是一个比较容易达到的星级。所以那些2星3星的店家~好好反省下吧 哈哈哈
人均消费
说完了星级来看看人均

深圳饭店人均消费最高1806元,最低4元,平均67元。嗯,平均67元,好像跟我的感觉差不多,基本上每次跟小伙伴们出去吃饭人均都在七八十到一百多吧,比平均值略高一点。唉,收入没有跑赢平均值,吃饭消费倒是跑赢了。。。怪不得恩格尔系数暴涨啊~[悲伤]
分布情况
再来看看分布情况,将人均消费分成几个范围组~
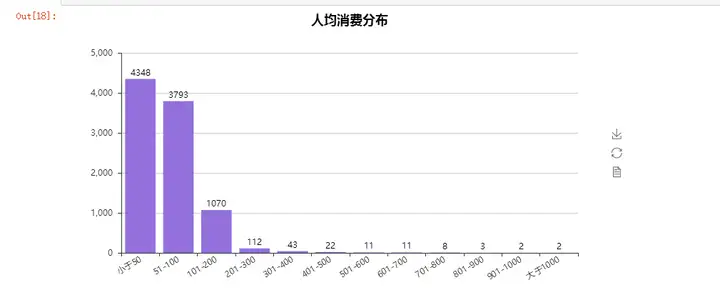
非常明显的一个右偏分布。。绝大部分人人均消费都是少于200元,普遍集中在100元以内(看到这里我心里又平衡了)。然而还是有少部分人人均消费大于1000的,对于这部分人我只想说,土豪求抱大腿啊啊啊。。。 看来这又给我一个小目标了啊,先吃它1000块。
这也反应出深圳这座城市中,大部分人都是普通的工薪阶级,人均消费能力相对较低,但同时依然有少量的资产阶级拥有远超大众的消费能力,贫富差距很大,两极分化严重,符合二八原则。
当然,深圳是一座年轻的城市,寻梦的城市,虽然贫富差距大,但总有不服输的追梦者创造出了不少神话,在这个越来越定型的社会中脱离了自身所处阶级,实现了阶级跃迁blablalbla.....(干了这碗鸡汤~)
最后,出于好奇,我看了下最贵的是哪家餐厅。

额,西安老刘家?1806元?我怎么没听过这家店。。。于是我去大众点评看了下。。好吧画风是这个样子的。。
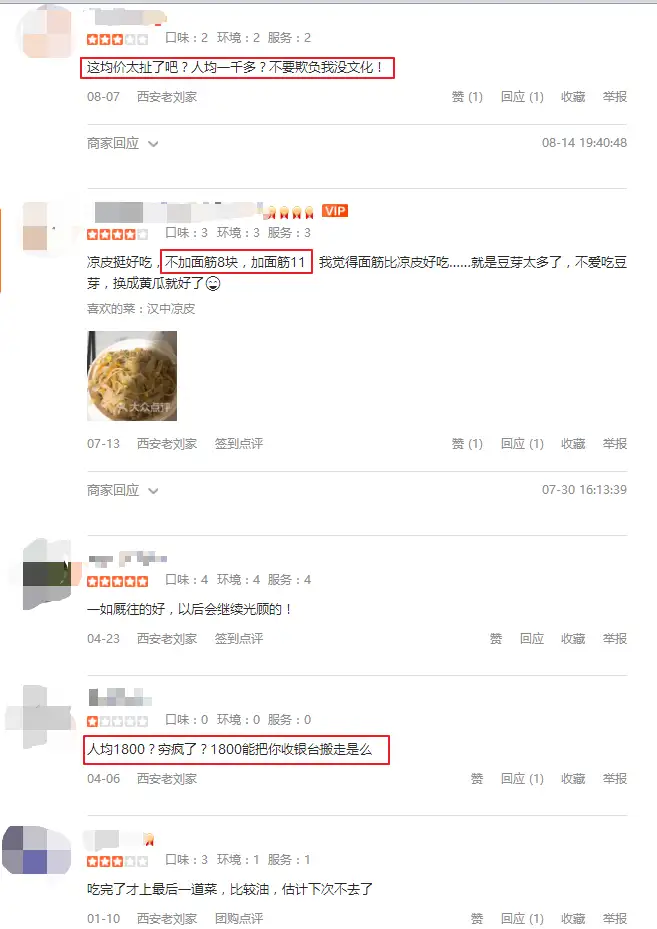
这充分告诉我们,有时候数据是不可信的,这数据太离谱了,不知道点评君是怎么得出这样的数据的~~~
人气情况
接下来我们看看人气情况。在这里,我把评论数的多少作为判定其人气高低的指标,毕竟人气高的话点评的人也会多,而无人问津的店自然也就没什么人点评~虽然这样判断不是很准确,但至少应该是正相关的,所以在没有想到(就是懒)更好的办法前就勉强拿来一用吧~(当然,如果一家店特别坑,也会导致大量的评论前来吐槽,但负面人气也是人气啊~现在不都流行负面炒作嘛)

那么评论最多的店有20094条评论,而最少的只有1条评论,平均是294条。
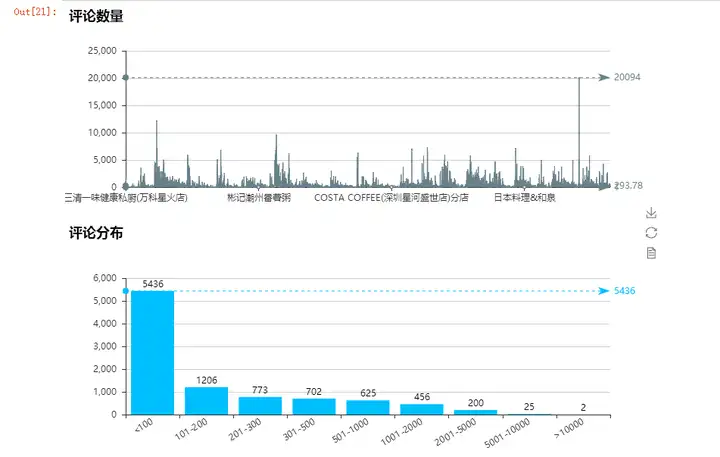
从图一可以看到只有一家店评论超过了2万,基本上大家还都是在1万条以下的。针对2万条评论的这家店我看了下,是“ 幸福西饼生日蛋糕(布心店)分店”。
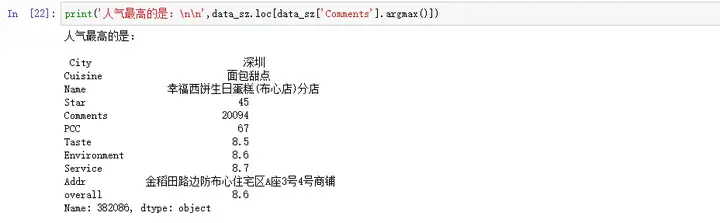
这么高的评论数不像是自然情况下的产生的,应该是有人为干扰因素,可能是店家搞的什么活动,类似于评论返现啊之类的造成的极端数据。
通常情况下,评论越多也就意味着店面规模或者品牌越大型,因为只有大型的店面,才能有更高的知名度,吸引更多的人过来就餐。小店面在这一点上是无法与大店媲美的,当然也会有那种几十年的老店就是一个小小的店面,然后人们口口相传名声打开了,但这种情况太少了,个例我们就不予考虑了。
那么我们看一下分布情况,跟人均消费一样,依然是个右偏分布,绝大部分都集中在100条以下。也就是绝大部分店面都是小店,真正能做大的、做成连锁品牌的店面非常的少,看来成功总是属于少部分人啊~
评分指标
在看看“口味”、“环境”、“服务”及“综合”等评分指标的情况~
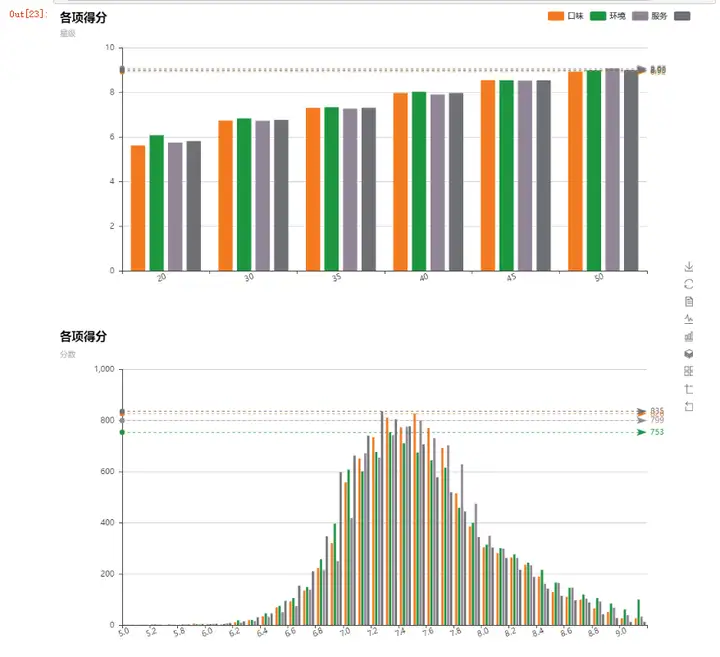
把口味、环境、服务及之前构建的综合指标放在一起查看其分布情况,可看出每一个指标都是呈正态分布的,大部分集中在7.2到7.6之间,剩下两端的分布很少。
然后我发现了一个有意思的现象,在2星的时候,环境比其他项的评分均分要高,这说明在星级较低的餐厅就餐时人们对于其环境的容忍度是比较高的。这或许是因为大家去一个低星级餐厅时已经对其环境有一定的心理预设。而随着星级越来越高,各项指标也越发平衡,说明饭店如果想得到更高的星级必须要均衡发展,不能偏科。同时,我还注意到5星级的饭店其服务得分会略微高于其他项,这说明越高星级的餐厅越重视服务水平。当然换句话说,这能否说明我们现在的很多餐厅,尤其是高档餐厅,相比于食物本身的味道它们更注重形式和服务表现。毕竟高级餐厅从口味上已经很难拉开距离了,这时候更多的附加价值软实力才是制胜根本。
综合水准

看起来深圳的各项指标还是挺均衡的~~~
OK~我知道大家一定很想知道这几项指标最高的分别都是哪些店面~~

以上饭店请联系我付广告费~~谢谢~
那从菜系的角度,什么菜系最贵?最受欢迎呢?

那么什么菜系最贵呢~来看看吧。海鲜~~~有木有想到呢,那最受欢迎的菜系咧~ 竟然是江浙菜,讲道理,我还以为是早茶呢~毕竟我大广东不是都喝早茶的么
最后,来看看星级和评分之间的关系~

查看星级与评分之间的关系,发现呈正相关,星级越高综合评分越高。跟我预计的差不多~~
三、机器学习
前面对数据进行了一个初步的探索,接下来想通过各项指标来预测星级,这是一个多分类问题,由于时间和精力有限,我决定把它转化为一个二分类问题,既判断一个餐厅是否为好餐厅。我将Star二值化,阈值取39,既简单的取星级4星以上的为好餐厅,标记为1,以下的为还需努力的,标记为0。然后将菜系由非数值标签处理为数值标签,本来应该再进行哑变量处理的,因为转为数值标签后,会有潜在顺序关系。但是不知道为何,进行了哑变量处理后,后面筛选特征重要性的时候就出问题了,由于时间有限,我后来就放弃了哑变量处理。所以这里多少是会有点误差的。

查看下处理后的数据

接下来划分feature和label

Star为标签,然后选Cuisine,Comments,PCC,Taste,Environment,Service作为特征。为什么不选City呢,因为城市都是深圳,大家都一样没有意义;不选Name的原因很简单,这又不是算卦,咱不看面相;不选Addr也是一个道理,咱也不看风水;不选overall是因为该分值就是由Taste,Environment,Service三个指标的均值构成的,相关性很高,可以舍去~
然后来计算下特征重要性,取前80%的特征作为训练特征。既Comments,Taste, Environment,Service 这四个特征~~

接着进行特征缩放,因为评论数量和评分之间相差过大,所以进行特征缩放,防止某一过大值挤压其他过小的值。

随后采取交叉验证测试模型得分,CV取10~
我尝试了 LinearSVC、SVM、朴素贝叶斯、随机森林及XGBoost模型,测量下来XGBoost模型表现最好,所以下一步就是对XGBoost模型进行调参~
啊,终于到了苦逼的调参时刻了~


最后调完超参数后,得分由原来的0.9489上升到了0.9497~~~撒花~~
那么假使有这么一家神秘的店面,其评论数为100,口味9.2,环境9.3,服务8.2,那么这家店值不值得去呢~

对的,分类为1,看来值得去~哈哈哈哈
四、总结及思考
仅针对本次数据,通过上面的分析可以得出以下结论:
两极分化。大众点评上有52.1%商家没有得到过任何点评,这说明有大量商家无人问津,无法依靠大众点评为他们引流 ,带来人气。但同时热门商家点评非常火爆,会进一步带动人气。这将会使得二者之间的差距愈来愈大。一线城市不管是餐厅数量还是菜系种类都领先于二三线城市,反应了一线城市的发展水平目前还是其他城市所无法比拟的,待在一线还是可以享受到很多便利的。重点二线城市发展速度很快,从餐厅数量和菜系种类上愈来愈逼近一线城市,甚至于出现了像天津这样在菜系种类上已经超越一线的城市。如果要去二线城市发展的话,可以优先考虑如杭州、南京、成都、天津等这样的重点二线城市。地区集中。大多数餐厅都集中在长三角、珠三角及环京地区,而西部地区则很少。反应了目前我国还是处在东南地区发达,西部地区欠发达的局面下。另外长三角、珠三角这两个超级城市群依然拥有很强的竞争力。星级分布服从正态分布,从3.5星到4星是一个门槛,跨越难度很大,有73.8%的店面无法跨越,但过了之后前景也很好。人均消费还是比较低的,大部分人都是工薪阶级,86.4%的人消费低于100元。但仍有部分土豪消费水平远超普通人,社会财富分布依然悬殊。口味、环境、服务指标都服从正态分布。另外随着星级越来越高,各项指标也越发平衡,饭店如果想得到更高的星级必须均衡发展。利用机器学习简单的对餐厅做好坏分类是可行的。本次分析的数据由于不是全量数据,所以结论难免会与真实情况存在差异。而且本次分析的也比较简陋,很多情况都没有考虑到,结论也略显稚嫩,部分地方或许会有纯堆砌数据却无深入分析的情况存在。这是我以后要尽量避免,努力提高自己的地方。另外,机器学习的部分非常简陋,特征的选取应该有更好的方法,而且标签的定义也过于简单。本来是想做多分类任务的,从指标来预测星级,不过由于时间问题只好改成了二分类任务了。这点在以后的迭代中需要更加完善下。
最后,为何我会闲着无聊写这篇报告呢?因为我失业了,待业在家啊!!!!!各位大佬们,求介绍工作,求内推啊~~~~~(此段划重点啊喂~,逃~)
广告时间:最后给自己代个盐~~欢迎大家有空时翻下我牌子,看看其他文章,顺便关注下专栏点个赞呗~
专栏:数据故事会~




